Longitudinal analysis: autocorrelation makes a difference
Back to posting after a long weekend and more than enough rugby coverage to last a few years. Anyway, back to linear models, where we usually assume normality, independence and homogeneous variances. In most statistics courses we live in a fantasy world where we meet all of the assumptions, but in real life—and trees and forests are no exceptions—there are plenty of occasions when we can badly deviate from one or more assumptions. In this post I present a simple example, where we have a number of Clones (genetically identical copies of a tree), which had between 2 and 4 Cores extracted, and each core was assessed for acoustic velocity (we care about it because it is inversely related to longitudinal shrinkage and its square is proportional to wood stiffness) every two millimeters. This small dataset is only a pilot for a much larger study currently underway.
At this stage I will ignore any relationship between the clones and focus on the core assessements. Let’s think for a moment; we have five replicates (which restrict the randomization) and four clones (A, B, C and D). We have (mostly) 2 to 4 cores (cylindrical pieces of wood covering from tree pith to cambium) within each tree, and we have longitudinal assessments for each core. I would have the expectation that, at least, successive assessments for each core are not independent; that is, assessments that are closer together are more similar than those that are farther apart. How does the data look like? The trellis plot shows trees using a Clone:Rep notation:
library(lattice)
xyplot(velocity ~ distance | Tree, group=Core,
data=cd, type=c('l'))
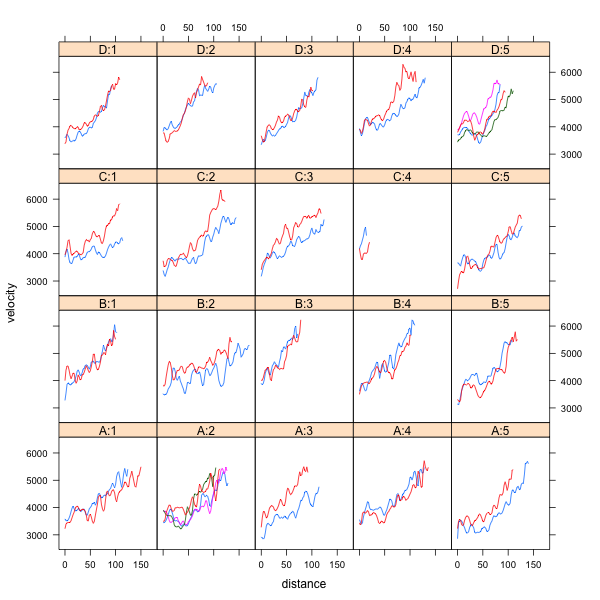
Incidentally, cores from Clone C in replicate four were damaged, so I dropped them from this example (real life is unbalanced as well!). Just in case, distance is in mm from the tree pith and velocity in m/s. Now we will fit an analysis that totally ignores any relationship between the successive assessments:
library(nlme)
lm1a <- lme(ACV ~ Clone*Distance,
random = ~ 1|Rep/Tree/Core, data=cd)
summary(lm1a)
Linear mixed-effects model fit by REML
Data: cd
AIC BIC logLik
34456.8 34526.28 -17216.4
Random effects:
Formula: ~1 | Rep
(Intercept)
StdDev: 120.3721
Formula: ~1 | Tree %in% Rep
(Intercept)
StdDev: 77.69231
Formula: ~1 | Core %in% Tree %in% Rep
(Intercept) Residual
StdDev: 264.6254 285.9208
Fixed effects: ACV ~ Clone * Distance
Value Std.Error DF t-value p-value
(Intercept) 3274.654 102.66291 2379 31.89715 0.0000
CloneB 537.829 127.93871 11 4.20380 0.0015
CloneC 209.945 137.10691 11 1.53125 0.1539
CloneD 293.840 124.08420 11 2.36807 0.0373
Distance 14.220 0.28607 2379 49.70873 0.0000
CloneB:distance -0.748 0.44852 2379 -1.66660 0.0957
CloneC:distance -0.140 0.45274 2379 -0.30977 0.7568
CloneD:distance 3.091 0.47002 2379 6.57573 0.0000
anova(lm1a)
numDF denDF F-value p-value
(Intercept) 1 2379 3847.011 <.0001
Clone 3 11 4.054 0.0363
distance 1 2379 7689.144 <.0001
Clone:distance 3 2379 22.468 <.0001
Incidentally, our assessment setup looks like this. The nice thing of having good technicians (Nigel made the tool frame), collaborating with other departments (Electrical Engineering, Michael and students designed the electronics and software for signal processing) and other universities (Uni of Auckland, where Paul—who cored the trees and ran the machine—works) is that one gets involved in really cool projects.

What happens if we actually allow for an autoregressive process?
lm1b <- lme(velocity ~ Clone*distance,
random = ~ 1|Rep/Tree/Core, data = cd,
correlation = corCAR1(value = 0.8,
form = ~ distance | Rep/Tree/Core))
summary(lm1b)
Linear mixed-effects model fit by REML
Data: ncd
AIC BIC logLik
\n29843.45 29918.72 -14908.73
Random effects:
Formula: ~1 | Rep
(Intercept)
StdDev: 60.8209
Formula: ~1 | Tree %in% Rep
(Intercept)
StdDev: 125.3225
Formula: ~1 | Core %in% Tree %in% Rep
(Intercept) Residual
StdDev: 0.3674224 405.2818
Correlation Structure: Continuous AR(1)
Formula: ~distance | Rep/Tree/Core
Parameter estimate(s):
Phi
\n0.9803545
Fixed effects: velocity ~ Clone * distance
Value Std.Error DF t-value p-value
(Intercept) 3297.517 127.98953 2379 25.763960 0.0000
CloneB 377.290 183.16795 11 2.059804 0.0639
CloneC 174.986 195.21327 11 0.896383 0.3892
CloneD 317.581 178.01710 11 1.783994 0.1020
distance 15.209 1.26593 2379 12.013979 0.0000
CloneB:distance 0.931 1.94652 2379 0.478342 0.6325
CloneC:distance -0.678 2.00308 2379 -0.338629 0.7349
CloneD:distance 2.677 1.95269 2379 1.371135 0.1705
anova(lm1b)
numDF denDF F-value p-value
(Intercept) 1 2379 5676.580 <.0001
Clone 3 11 2.483 0.1152
distance 1 2379 492.957 <.0001
Clone:distance 3 2379 0.963 0.4094
Oops! What happened to the significance of Clone and its interaction with distance? The perils of ignoring the independence assumption. But, wait, isn’t an AR(1) process too simplistic to model the autocorrelation (as pointed out by D.J. Keenan when criticizing IPCC’s models and discussing Richard Mueller’s new BEST project models)? In this case, probably not, as we have a mostly increasing response, where we have a clue of the processes driving the change and with far less noise than climate data.
Could we improve upon this model? Sure! We could add heterogeneous variances, explore non-linearities, take into account the genetic relationship between the trees, run the whole thing in asreml (so it is faster), etc. Nevertheless, at this point you can get an idea of some of the issues (or should I call them niceties?) involved in the analysis of experiments.