Excel, fanaticism and R
This week I’ve been feeling tired of excessive fanaticism (or zealotry) of open source software (OSS) and R in general. I do use a fair amount of OSS and pushed for the adoption of R in our courses; in fact, I do think OSS is a Good ThingTM. I do not like, however, constant yabbering on why using exclusively OSS in science is a good idea and the reduction of science to repeatability‡ and computability (both of which I covered in my previous post). I also dislike the snobbery of ‘you shall use R and not Excel at all, because the latter is evil’ (going back ages).
We often have several experiments running during the year and most of the time we do not bother setting up a data base to keep data. Doing that would essentially mean that I would have to do it, and I have a few things more important to do. Therefore, many data sets end up in… (drum roll here) Microsoft Excel.
How should a researcher setup data in Excel? Rather than reinventing the wheel, I’ll use a(n) (im)perfect diagram that I found years ago in a Genstat manual.
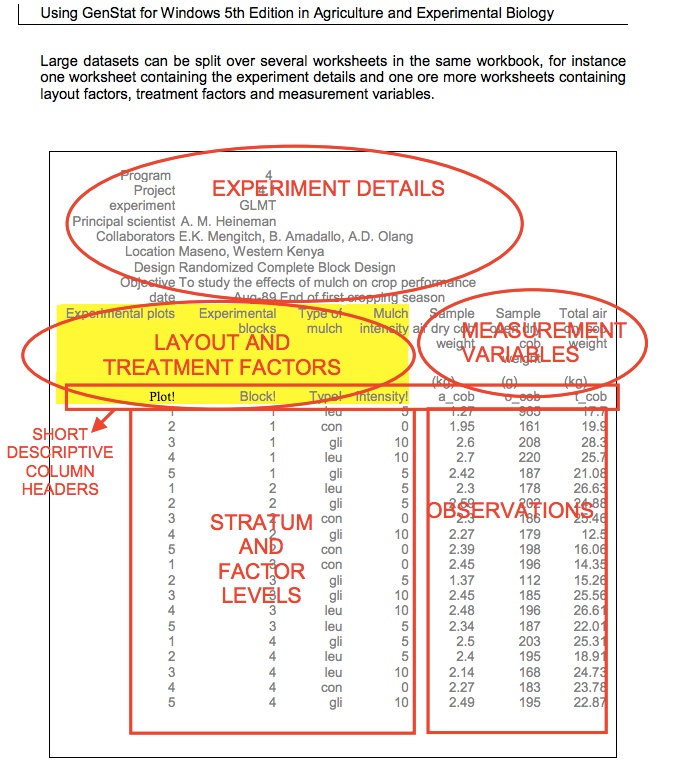
I like it because:
- It makes clear how to setup the experimental and/or sampling structure; one can handle any design with enough columns.
- It also manages any number of traits assessed in the experimental units.
- It contains metadata in the first few rows, which can be easily skipped when reading the file. I normally convert Excel files to text and then I skip the first few lines (using
skipin R orfirstobsin SAS).
People doing data analysis often start convulsing at the mention of Excel; personally, I deeply dislike it for analyses but it makes data entry very easy, and even a monkey can understand how to use it (I’ve seen them typing, I swear). The secret for sane use is to use Excel only for data entry; any data manipulation (subsetting, merging, derived variables, etc.) or analysis is done in statistical software (I use either R or SAS for general statistics, ASReml for quantitative genetics).
It is far from a perfect solution but it fits in the realm of the possible and, considering all my work responsibilities, it’s a reasonable use of my time. Would it be possible that someone makes a weird change in the spreadsheet? Yes. Could you fart while moving the mouse and create a non-obvious side effect? Yes, I guess so. Will it make your life easier, and make possible to complete your research projects? Yes sir!
P.S. One could even save data using a text-based format (e.g. csv, tab-delimited) and use Excel only as a front-end for data entry. Other spreadsheets are of course equally useful.
P.S.2. Some of my data are machine-generated (e.g. by acoustic scanners and NIR spectroscopy) and get dumped by the machine in a separate—usually very wide; for example 2000 columns—text file for each sample. I never put them in Excel, but read them directly (a directory-full of them) in to R for manipulation and analysis.
‡As an interesting aside, the post A summary of the evidence that most published research is false provides a good summary for the need to freak out about repeatability.