Statistics unplugged
How much does statistical software help and how much it interferes when teaching statistical concepts? Software used in the practice of statistics (say R, SAS, Stata, etc) brings to the party a mental model that it’s often alien to students, while being highly optimized for practitioners. It is possible to introduce a minimum of distraction while focusing on teaching concepts, although it requires careful choice of a subset of functionality. Almost invariably some students get stuck with the software and everything goes downhill from there; the student moved from struggling with a concept to struggling with syntax (Do I use a parenthesis here?).
I am a big fan of Tim Bell’s Computer Science Unplugged, a program for teaching Computer Science’s ideas at primary and secondary school without using computers.
This type of instruction makes me question both how we teach statistics and at what level we can start teaching statistics. The good news is that the New Zealand school curriculum includes statistics in secondary school, for which there is increasing number of resources. However, I think we could be targeting students even earlier.
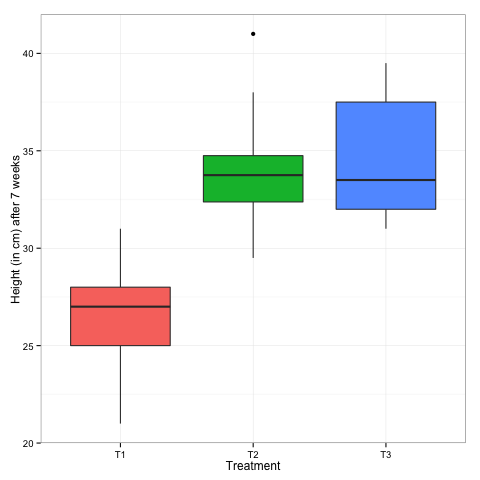
This year my wife was helping primary school students participating in a science fair and I ended up volunteering to introduce them to some basic concepts so they could design their own experiments. Students got the idea of the need for replication, randomization, etc. based on a simple question: Did one of them have special powers to guess the result of flipping a coin? (Of course this is Fisher’s tea-drinking-lady-experiment, but no 10 year old cares about tea, while at least some of them care about super powers). After the discussion one of them ran a very cool experiment on the effect of liquefaction on the growth of native grasses (very pertinent in post-earthquake Christchurch), with 20 replicates (pots) for each treatment. He got the concepts behind the experiment; software just entered the scene when we needed to confirm our understanding of the results in a visual way:
People tell me that teaching stats without a computer is like teaching chemistry without a lab or doing astronomy without a telescope, or… you get the idea. At the same time, there are some books that describe some class activities that do not need a computer; e.g. Gelman’s Teaching Statistics: A Bag of Tricks. (Incidentally, why is that book so friggin’ expensive?)
Back to uni #
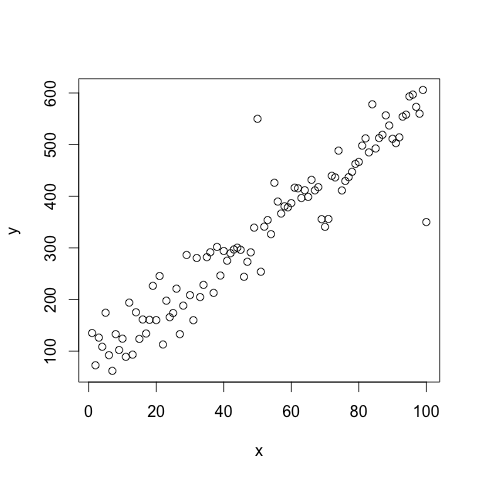
Back from primary school kiddies to a regression course at university. Let’s say that we have two variables, x & y, and that we want to regress y (response) on x (predictor) and get diagnostic plots. In R we could simulate some data and plot the relationship using something like this:
# Basic regression data
n <- 100
x <- 1:n
y <- 70 + x*5 + rnorm(n, 0, 40)
# Changing couple of points and plotting
y[50] <- 550
y[100] <- 350
plot(y ~ x)
We can the fit the linear regression and get some diagnostic plots using:
# Regression and diagnostics
m1 <- lm(y ~ x)
par(mfrow = c(2,2))
plot(m1)
par(mfrow = c(1,1))
Regression and diagnostics #
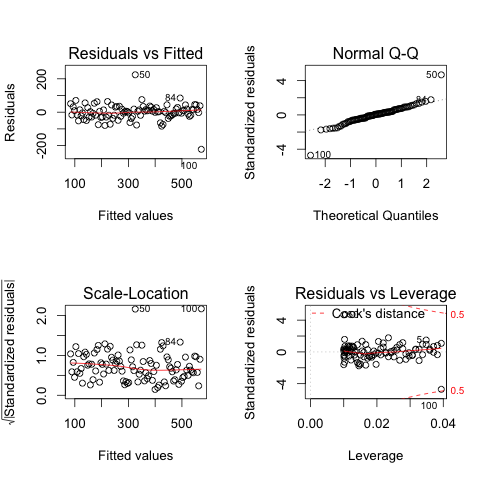
If we ask students to explain the 4th plot—which displays discrepancy (how far a point is from the general trend) on leverage (how far is a point from the center of mass, pivot of the regression)—many of them will struggle to say what is going on in that plot. At that moment one could go and calculate the Hat matrix of the regression (
$$X (X'X)^{-1} X'$$) and get leverage from the diagonal, etc and students will get a foggy idea. Another, probably better, option is to present the issue as a physical system on which students already have experience. A good candidate for physical system is using a seesaw, because many (perhaps most) students experienced playing in one as children.
Take your students to a playground (luckily there is one next to uni), get them playing with a seesaw. The influence of a point is related to the product of leverage (how far from the pivot we are applying force) and discrepancy (how big is the force applied). The influence of a point on the estimated regression coefficients will be very large when we apply a strong force far from the pivot (as in our point y[100]), just as it happens in a seesaw. We can apply lots of force (discrepancy) near the pivot (as in our point y[50]) and little will happen. Students like mucking around with the seesaw and, more importantly, they remember.

Analogy can go only so far. Some times a physical analogy like a quincunx (to demonstrate the central limit theorem) ends up being more confusing than using an example with variables that are more meaningful for students.
I don’t know what is the maximum proportion of course content that could be replaced by using props, experiments, animations, software specifically designed to make a point (rather than to run analysis), etc. I do know that we still need to introduce ‘proper’ statistical software—at some point students have to face praxis. Nevertheless, developing an intuitive understanding is vital to move from performing monkeys; that is, people clicking on menus or going over the motion of copy/pasting code without understanding what’s going on in the analyses.
I’d like to hear if you have any favorite demos/props/etc when explaining statistical concepts.
P.S. In this post I don’t care if you love stats software, but I specifically care about helping learners who struggle understanding concepts.