Less wordy R
The Swarm Lab presents a nice comparison of R and Python code for a simple (read ‘one could do it in Excel’) problem. The example works, but I was surprised by how wordy the R code was and decided to check if one could easily produce a shorter version.
The beginning is pretty much the same, although I’ll use ggplot2 rather than lattice, because it will be a lot easier (and shorter) to get the desired appearance for the plots:
library(Quandl)
library(ggplot2)
# Load data from Quandl
my.data <- Quandl("TPC/HIST_RECEIPT",
start_date = "1945-12-31",
end_date = "2013-12-31")
The whole example relies on only three variables and—as I am not great at typing—I tend to work with shorter variable names. I directly changed the names for variables 1 to 3:
# Display first lines of the data frame
# and set short names for first three columns
head(my.data)
names(my.data)[1:3] <- c('year', 'indtax', 'corptax')
It is a lot easier to compare the regression lines if we change the shape of the data set from wide to long, where there is one variable for year, one for tax type, and one for the actual tax rate. It would be possible to use one of Hadley’s packages to get a simpler syntax for this, but I decided to stick to the minimum set of requirements:
# Change shape to fit both regressions simultaneously
mdlong <- reshape(my.data[, 1:3],
idvar = 'year', times = c('Individual', 'Corporate'),
varying = list(2:3), direction = 'long')
mdlong <- with(mdlong, taxtype <- factor(time))
And now we are ready to produce the plots. The first one can be a rough cut to see if we get the right elements:
ggplot(mdlong,
aes(x = year, y = indtax, color = taxtype)) +
geom_point() + geom_line() + geom_smooth(method = 'lm')
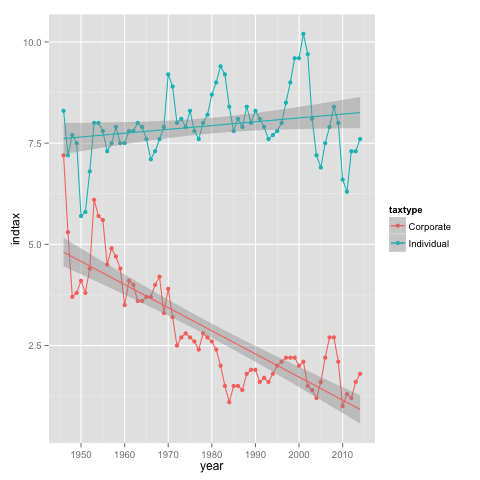
Yes, this one has the points, lines, linear regression and 95% confidence intervals for the mean predicted responses, but we still need to get rid of the grey background and get black labels (theme_bw()), set the right axis labels and ticks (scale_x... scale_y...) and set the right color palette for points and lines (scale_colour_manual) and filling the confidence intervals (scale_colour_fill) like so:
# Plotting the graph (first match color palette) and put the regression
# lines as well
serious.palette <- c('#AD3333', '#00526D')
ggplot(mdlong, aes(x = year, y = indtax, color = taxtype)) +
geom_point() + geom_line() +
geom_smooth(method = 'lm', aes(fill = taxtype)) +
theme_bw() +
scale_y_continuous('Income taxes (% of GDP)',
breaks = seq(0, 12, 2), minor_breaks = NULL) +
scale_x_date('Fiscal year', minor_breaks = NULL) +
scale_colour_manual(values=serious.palette) +
scale_fill_manual(values=serious.palette)
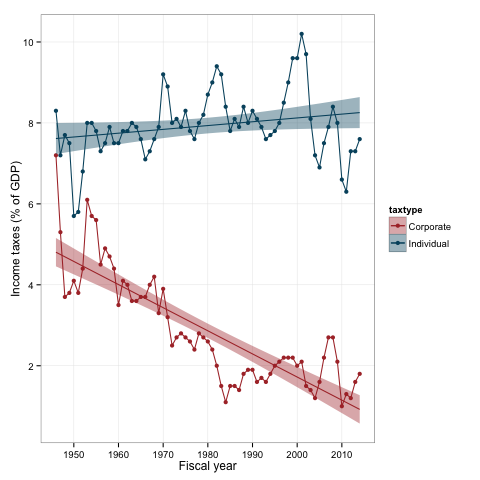
One can still change font sizes to match the original plots, reposition the legend, change the aspect ratio while saving the png graphs (all simple statements) but you get the idea. If now we move to fitting the regression lines:
# Fitting a regression with dummy variables
m1 <- lm(indtax ~ year*taxtype, data = mdlong)
summary(m1)
# The regressions have different intercepts and slopes
# Call:
# lm(formula = indtax ~ year * taxtype, data = mdlong)
#
# Residuals:
# Min 1Q Median 3Q Max
# -1.95221 -0.44303 -0.05731 0.35749 2.39415
#
# Coefficients:
# Estimate Std. Error t value Pr(>|t|)
# (Intercept) 3.435e+00 1.040e-01 33.01 <2e-16 ***
# year -1.564e-04 1.278e-05 -12.23 <2e-16 ***
# taxtypeIndividual 4.406e+00 1.471e-01 29.94 <2e-16 ***
# year:taxtypeIndividual 1.822e-04 1.808e-05 10.08 <2e-16 ***
# ---
# Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
#
# Residual standard error: 0.7724 on 134 degrees of freedom
# Multiple R-squared: 0.9245, Adjusted R-squared: 0.9228
# F-statistic: 546.9 on 3 and 134 DF, p-value: < 2.2e-16
This gives the regression coefficients for Corporate (3.45 - 1.564e-04 year) and Individual ([3.45 + 4.41] + [-1.564e-04 + 1.822e-04] year or 7.84 + 2.58e-05 year). As a bonus you get the comparison between regression lines.
In R as a second language I pointed out that ‘brevity reduces the time between thinking and implementation, so we can move on and keep on trying new ideas’. Some times it seriously does.