Collecting results of the New Zealand General Elections
I was reading an article about the results of our latest elections where I was having a look at the spatial pattern for votes in my city.
I was wondering how would I go over obtaining the data for something like that and went to the Electoral Commission, which has this neat page with links to CSV files with results at the voting place level. The CSV files have results for each of the candidates in the first few rows (which I didn’t care about) and at the party level later in the file.
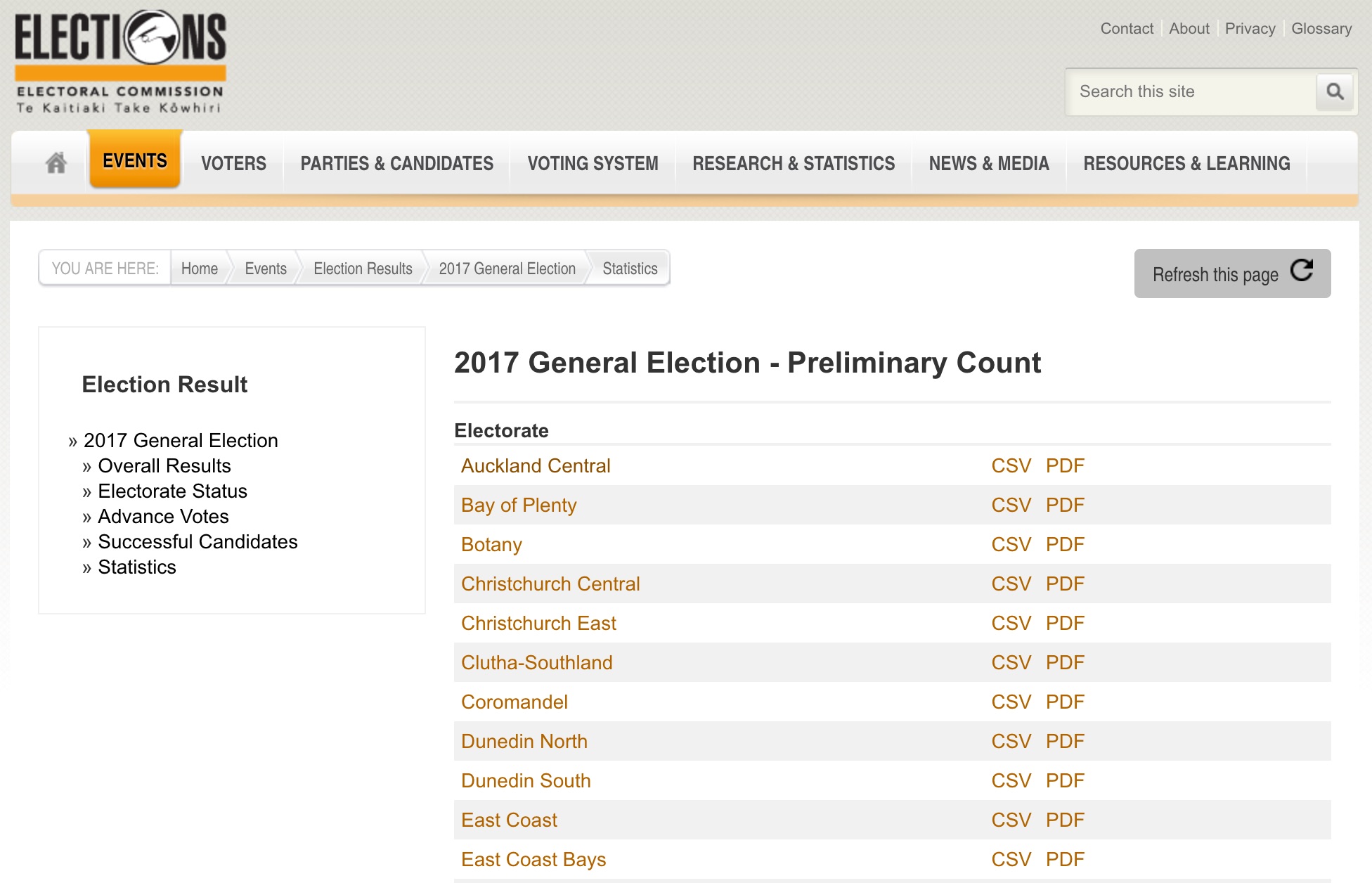
As I could see it I needed to:
- Read the Electoral Commission website and extract the table that contains the links to all CSV files.
- Read each of the files and i- extract the electorate name, ii- skipping all the candidates votes, followed by iii-reading the party vote.
- Remove sub-totals and other junk from the files.
- Geocode the addresses
- Use the data for whatever else I wanted (exam question anyone?).
So I first loaded the needed packages and read the list of CSV files:
library(magrittr)
library(tidyverse)
library(rvest)
library(stringr)
library(ggmap)
# Extract list of CSV file names containing voting place data
voting_place %
html_nodes('table') %>% html_nodes('a') %>%
html_attr('href') %>% str_subset('csv') %>%
paste('http://www.electionresults.govt.nz/electionresults_2017_preliminary','/',., sep = '') -> voting_place_list
Then wrote a couple of functions to, first, read the whole file, get the electorate name and, second, detect where the party vote starts to keep from that line onwards. Rather than explicitly looping over the list of CSV file names, I used map_dfr from the purrr package to extract the data and join all the results by row.
get_electorate <- function(row) {
row %>% str_split(pattern = ',') %>%
unlist() %>% .[1] %>% str_split(pattern = '-') %>%
unlist() %>% .[1] %>% str_trim() -> elect
return(elect)
}
# Function to read only party-level votes from voting places
extract_party_vote <- function(file_name) {
all_records <- read_lines(file_name)
electorate <- get_electorate(all_records[1])
start_party <- grep('Party Vote', all_records)
party_records <- all_records[start_party:length(all_records)]
party_records_df <- read.table(text = party_records, sep = ',',
fill = TRUE, header = TRUE, quote = '"',
stringsAsFactors = FALSE)
names(party_records_df)[1:2] <- c('neighbourhood', 'address')
party_records_df$electorate <- electorate
return(party_records_df)
}
# Download files and create dataframe
vote_by_place <- map_dfr(voting_place_list, extract_party_vote)
Cleaning the data and summarising by voting place (as one can vote for several electorates in a single place) is fairly straightforward. I appended the string Mobile to mobile teams that visited places like retirement homes, hospitals, prisons, etc:
# Remove TOTAL and empty records
vote_by_place %>%
filter(address != '') %>%
mutate(neighbourhood = ifelse(neighbourhood == '',
paste(electorate, 'Mobile'), neighbourhood)) %>%
group_by(neighbourhood, address) %>%
summarise_at(vars(ACT.New.Zealand:Informal.Party.Votes),
sum, na.rm = TRUE) -> clean_vote_by_place
Geolocation is the not-working-very-well part right now. First, I had problems with Google (beyond the 1,000 places limit for the query). Then I went for using the Data Science Kit as the source but, even excluding the mobile places, it was a bit hit and miss for geolocation, particularly as the format of some address (like corner of X and Y) is not the best for a search.
In addition, either of the two sources for geolocation work really slowly and may produce a lot of output. Using sink() could be a good idea to not end up with output for roughly 3,000 queries. I did try the mutate_geocode() function, but didn’t work out properly.
# Geolocate voting places
get_geoloc <- function(record) {
address <- paste(record$address, 'New Zealand', sep = ', ')
where <- try(geocode(address, output = "latlona", source = "dsk"),
silent = TRUE)
where$address <- as.character(address)
where$locality <- as.character(record$neighbourhood)
return(where)
}
# Sending whole row to the map function
clean_vote_by_place %>%
pmap_dfr(., lift_ld(get_geoloc)) -> geoloc_voting_places
David Robinson was kind enough to help me with the last line of the script, although he updated the advise to:
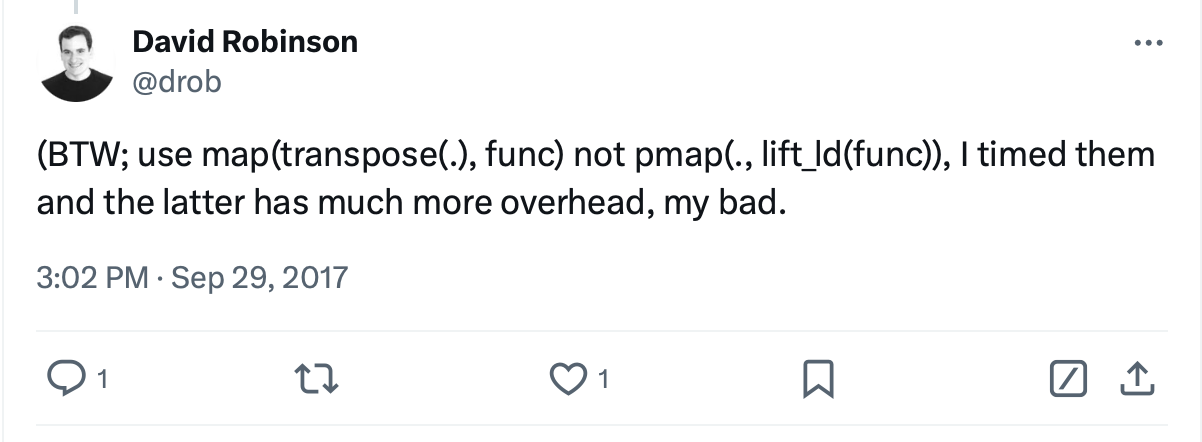
Given the size of my dataset, either option took bugger all time, although I have to say that
clean_vote_by_place %>%
mutate(map(transpose(.), get_geoloc)) -> etc
looks prettier.
Once the data are geolocated, creating a visualisation is not so hard. Even old dogs can find their way to do that!