On R, bloggers, politics, sex, alcohol and rock & roll
Yesterday morning at 7 am I was outside walking the dog before getting a taxi to go to the airport to catch a plane to travel from Christchurch to Blenheim (now I can breath after reading without a pause). It was raining cats and dogs while I was walking doggyo, thinking of a post idea for Quantum Forest; something that I could work on without a computer. Then I remembered that I told Tal Galili that I would ‘mention r-bloggers’ in a future post. Well, Tal, this is it.
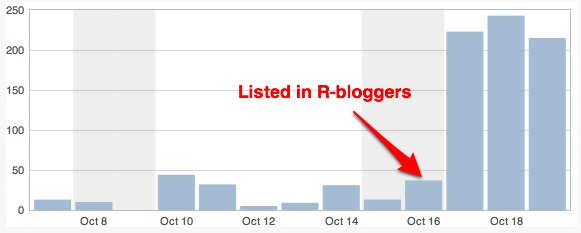
I started this blog on 4th October and I thought ‘I could write a few things and see how it goes. I may even get 10 people a day reading this blog’. I reached that number almost immediately and I was thinking that, if I kept going at it, I could eventually reach 50 people. Then I came across R-bloggers and, after some hesitation, I submitted this blog to Tal’s web site. I jumped to over 200 people a day visiting the blog (see below) and even got comments! I repeat: I was writing about mixed models and got comments!
As I point out in the ‘About’ page, this is not an ‘R blog’ but a blog about statistics and data analysis in general, that mostly uses R as a vehicle to express ideas. There will be some Python (my favorite language) and, maybe, other tools; however, the ideas are more important than the syntax. Nevertheless, R has democratized the practice of statistics, as well as facilitated the production of some very interesting visuals. Once thing was clear to me: I did not want to write about ‘data visualization’, which is receiving a lot (I dare to say too much) attention in the R world. Most infographics produce the same reaction on me as choirs and mimes; which is to say, they bore me to tears (apologies if you are a choir-singer mime in your spare time). I want to write a bit about analysis and models and ‘bread and butter’ issues, because I think that they are many times ignored by people chasing the latest smoke and mirrors.
I have to say that I am learning a lot from comments, particularly people suggesting packages that I didn’t even know that existed. I am also learning about spam-comments and I wish there was a horrible place where spammers would go and suffer for eternity (together with pedophiles, torturers and other not-so-nice seedy characters). I am thankful to Tal mostly for putting the work to create a repository of R blogs; when I have some free time I often wander around looking for some interesting explanation to an R problem that is bugging me. As Tolkien said: ‘Not all those who wander are lost’.
Politics #
Most of my professional life I have dealt with, let’s say, ‘agricultural’ statistics; that is, designed experiments, linear mixed models (mostly frequentist, but sometimes Bayesian), often with pedigrees. One of my pet peeves (and somewhat political issue) is that many statisticians—particularly in mathematics departments—tend to look down on ‘bread and butter’ work. They seem to forget that experiments and breeding/genetics have been the basis of many theoretical developments and that we deal with heavily multivariate data, longitudinal data, spatial data, models with sometimes hundreds of covariance components or, if you are into genomics, models with tens of thousands of random effects.
There is also the politics of software, where in the R community there is a strong bias against any package that is not free (sensu both speech and beer). At some level I share the ideal of having free access to tools, which make the practice of statistics/data analyses available to a large number of people. At another level, it seems counterproductive to work with substandard tools and to go for lesser models only because ‘package X can’t deal with the model that I would like to fit’. This is just another example of software defining our field, which was (and still is) a common accusation pointed towards SAS. In contrast, in this blog you will see several references to
ASReml-R a commercial mixed-models package, which I tend to use because (as far as I know) there is nothing at the moment that comes close to its functionality. If I pay for my computer running MS Windows or OS X (far from being paradigms of openness), how can I justify being dogmatic about using a commercial R package (particularly if I can access it via academic or nonprofit pricing)?
Sex and alcohol #
As I pointed out above, most of my work has dealt with forestry/agriculture. Nevertheless, this year I have become more interested in the relationship between statistics and public policy issues; for example, minimum wage and unemployment, which I covered as a simple example in this blog. I have to thank my colleague Eric Crampton (in Canterbury’s Department of Economics) for igniting my interest on the use and misuse of statistics, and their interaction with economics, to justify all sort of restrictions and interventions in society. There are very interesting datasets in this area available in, for example, Statistics New Zealand that could be analyzed and would make very interesting case studies for teaching stats. There is a quote by H.G. Wells that comes to mind:
Statistical thinking will one day be as necessary for efficient citizenship as the ability to read and write.
Rock & roll? This is getting too long, so I will leave music for another time.