The beauty of code vectorisation
I came across this problem in Twitter:

The basic pieces of the problem are:
- We need to generate pseudorandom numbers with an identical distribution, add them up until they go over 1 and report back how many numbers we needed to achieve that condition.
- Well, do the above “quite a few times” and take the average, which should converge to the number e (2.7182…).
In most traditional languages, the first step would look more or less like this:
counter <- 0
while(total <= 1) {
total <- total + runif(1)
counter <- counter + 1
}
or by setting a “big enough” predefined number of iterations:
total <- 0
for(counter in 1:100) {
total <- total + runif(1)
if(total > 1) return(counter)
}
We would need to define another loop to run the above code “quite a few times”, which for ten million times (10^7) could look like:
results <- 0
average <- 0
for(iteration in 1:10^7) {
total <- 0
counter <- 0
while(total < 1) {
total <- total + runif(1)
counter <- counter + 1
}
results <- results + counter
average <- results/iteration
}
However, we are working with R, which happens to be an array-based (or matrix-based, or vector-based) language and it has functionality for data processing. A first, rough approach could be:
mean(vapply(1:10^7,
FUN.VALUE = 1, FUN = function(x) {
sum <- 0
i <- 1
while(TRUE) {
sum <- sum + runif(1)
if(sum > 1) return(i) else {
i <- i+1
next
}
}
}))
It can be much shorter if, rather than thinking of loops, we think of vectors:
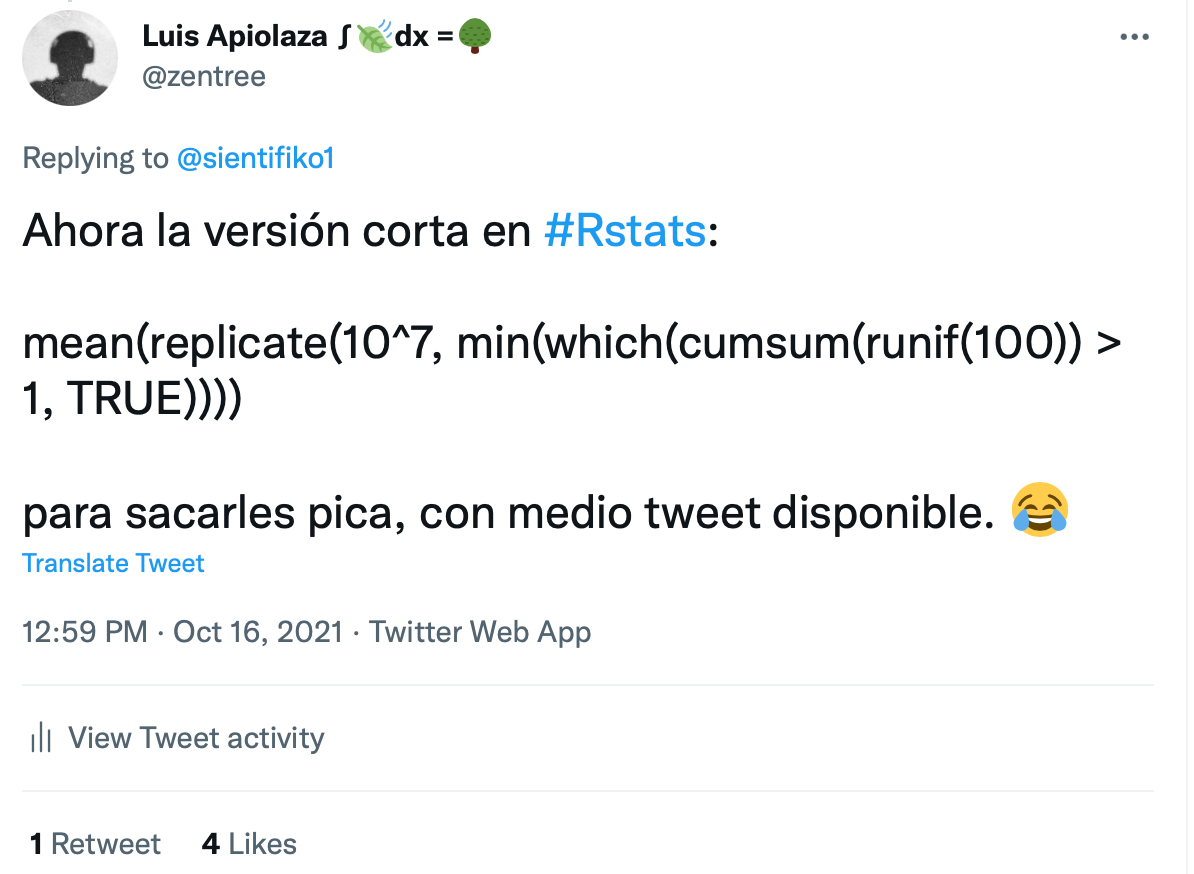
mean(replicate(10^7,
min(which(cumsum(runif(100)) > 1, TRUE))))
The code works the following way:
- Generate 100 uniformly distributed random numbers (0, 1):
runif(100) - Calculate the cumulative sum of the 100 numbers:
cumsum() - Check if the cumulative sum is greater than 1:
which(cumsum() > 1, TRUE) - Find the minimum position that meets the criterion:
min() - Replicate that process ten million times:
replicate(10^7, ) - Take the average of all the positions:
mean()
Half a tweet to solve the problem. Look, ma. No explicit loops!