Some regressions on school data
Eric and I have been exchanging emails about potential analyses for the school data and he published a first draft model in Offsetting Behaviour. I have kept on doing mostly data exploration while we get a definitive full dataset, and looking at some of the pictures I thought we could present a model with fewer predictors.
The starting point is the standards dataset I created in the previous post:
# Make authority a factor
standards$authority <- factor(standards$authority)
# Plot relationship between school size and number of FTTE
# There seems to be a separate trend for secondary schools
qplot(total.roll, teachers.ftte,
data = standards, color = school.type)
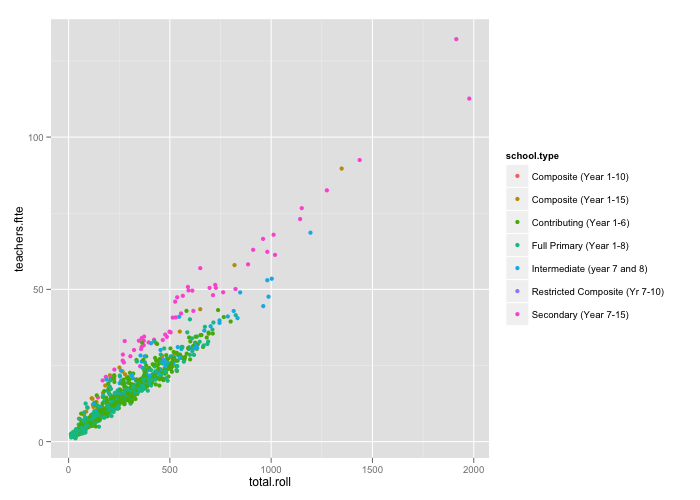
# Create a factor for secondary schools versus the rest
standards$secondary <- factor(ifelse(standards$school.type == 'Secondary (Year 7-15)',
'Yes', 'No'))
# Plot the relationship between number of students per FTTE
# and type of school
qplot(secondary, total.roll/teachers.ftte,
data = standards, geom = 'boxplot',
ylab = 'Number of students per FTTE')
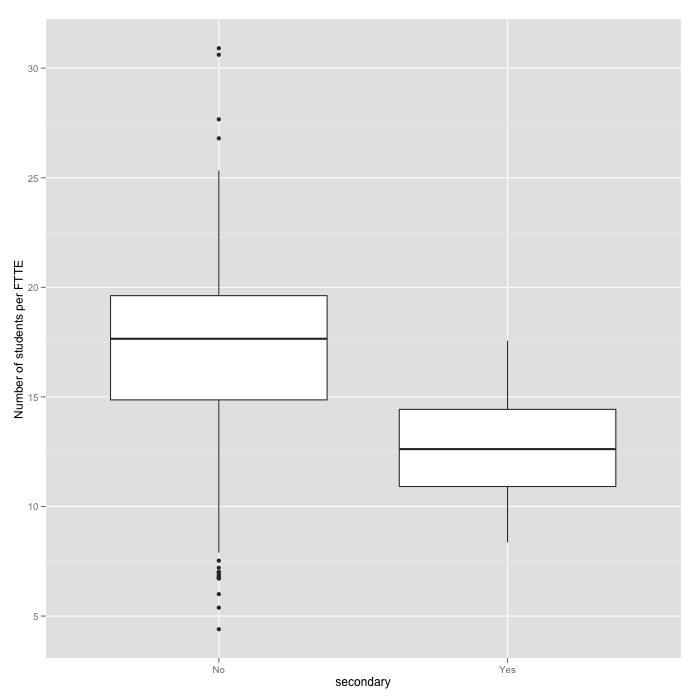
Now we fit a model where we are trying to predict reading standards achievement per school accounting for decile, authority , proportion of non-european students, secondary schools versus the rest, and a different effect of number of students per FTTE for secondary and non-secondary schools.
standards$students.per.ftte <- with(standards,
total.roll/teachers.ftte)
# Decile2 is just a numeric version of decile (rather than a factor)
m1e <- lm(reading.OK ~ decile2 + I(decile2^2) +
authority + I(1 - prop.euro) + secondary*students.per.ftte,
data = standards, weights = total.roll)
summary(m1e)
#Coefficients:
# Estimate Std. Error t value Pr(>|t|)
#(Intercept) 0.6164089 0.0305197 20.197 < 2e-16 ***
#decile2 0.0422733 0.0060756 6.958 6.24e-12 ***
#I(decile2^2) -0.0015441 0.0004532 -3.407 0.000682 ***
#authorityState: Not integrated -0.0440261 0.0089038 -4.945 8.94e-07 ***
#I(1 - prop.euro) -0.0834869 0.0181453 -4.601 4.74e-06 ***
#secondaryYes -0.2847035 0.0587674 -4.845 1.47e-06 ***
#students.per.ftte 0.0023512 0.0011706 2.009 0.044854 *
#secondaryYes:students.per.ftte 0.0167085 0.0040847 4.091 4.65e-05 ***
---
#Residual standard error: 1.535 on 999 degrees of freedom
# (3 observations deleted due to missingness)
#Multiple R-squared: 0.4942, Adjusted R-squared: 0.4906
#F-statistic: 139.4 on 7 and 999 DF, p-value: < 2.2e-16
The residuals are still a bit of a mess:
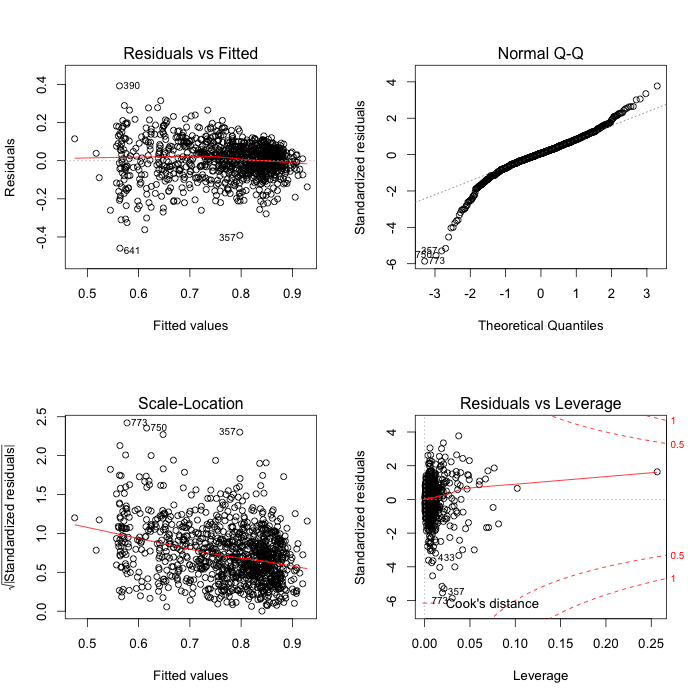
If we remember my previous post decile accounted for 45% of variation and we explain 4% more through the additional predictors. Non-integrated schools have lower performance, a higher proportion of non-European students reduce performance, secondary schools have lower performance and larger classes tend to perform better (Eric suggests reverse causality, I’m agnostic at this stage), although the rate of improvement changes between secondary and non-secondary schools. In contrast with Eric, I didn’t fit separate ethnicities as those predictors are related to each other and constrained to add up to one.
Of course this model is very preliminary, and a quick look at the coefficients will show that changes on any predictors besides decile will move the response by a very small amount (despite the tiny p-values and numerous stars next to them). The distribution of residuals is still heavy-tailed and there are plenty of questions about data quality; I’ll quote Eric here:
But differences in performance among schools of the same decile by definition have to be about something other than decile. I can’t tell from this data whether it’s differences in stat-juking, differences in unobserved characteristics of entering students, differences in school pedagogy, or something else. But there’s something here that bears explaining.